jQuery 的基础就是查询,选择器是他最大的特性和优点。我们要获取 jQuery 对象,选择器的重要性不言而喻。
关键的正则式
|
这是一个简单检测 HTML 字符串的正则表达式。
分解理清正则表达式
(@:学习的博客中教会了我一个挺好的分解思路,整理如下:)
1. 拿开表达式的 ^ 开头和 $ 结尾,从剩下的表达式开始一层层拆解
首先拿到这个
可以发现,在这个 pattern 中,其实是 (?:pattern) 形式。作用是:“匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用”。
2. 找到分支符号 “|”,逐个拆解
得到:
- \s(<[\w\W]+>)[^>]
- #([\w-]*)
3. 分支拆解
第一段:
- \s*: 匹配任何空白字符,包括空格、制表符、换页符等等 零次或多次 等价于{0,}
- (pattern): 匹配pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,使用 $0…$9 属性
- [\w\W]+: 匹配于’[A-Za-z0-9_]’或[^A-Za-z0-9_]’ 一次或多次, 等价{1,}
- (<[\w\W]+>): 这个表示字符串里要包含用<>包含的字符,例如
,
等等都是符合要求的 - [^>]*: 负值字符集合,字符串尾部是除了>的任意字符或者没有字符,零次或多次等价于{0,}
第二段: - 匹配结尾带上#号的任意字符,包括下划线与-
也就是说,这段正则表达式是匹配 HTML 标记和 ID 表达式(”<” 前面可以匹配任何空白字符,包括空格、制表符、换行符 etc)
P.s.
exec() 的返回值—— Array() || null,包括:
- [0]: 匹配的全部字符串
- [1], … [n]: 括号中的分组捕获
( 其实就是说,当正则表达式有多个分支(组)的话,当前检测的字符串是在哪个组的规则下匹配到的,就会存在相应索引的元素中。) - index: 匹配到的字符位于原始字符串的基于 0 的索引值
- input: 原始字符串var rquickExp = /^(?:\s*(<[\w\W]+>)[^>]*|#([\w-]*))$/;// HTML 字符串var str = '<div></div>',str2 = '<div id="test"></div>',str3 = '[?\f\n\r\t\v]<div id="testt"></div>';// idvar str4 = '#testtt',str5 = '#_ttest-';console.log(1, rquickExp.exec(str));console.log(2, rquickExp.exec(str2));console.log(3, rquickExp.exec(str3));console.log(4, rquickExp.exec(str4));console.log(5, rquickExp.exec(str5));
执行结果:
选择器接口
接受形式
jQuery 的选择器接受 9 种形式:
jQuery的反模式,非职责单一深受开发者喜欢,一个接口承载的职责越多内部处理就越复杂了
学习的博客中提到了 jQuery 的反模式,自己便搜了相关内容,可以查阅:聊聊jQuery的反模式
jQuery 查询到的对象是 DOM 元素,查询结果(可能是单个元素或者一个集合)会存储到一个新建的 jQuery 对象中。
init() 逻辑结构
源码(仅保留结构):
结构:
- 处理了 selector 为 “”、null、undefined、false 这些情况,直接返回 this(增加程序的健壮性?)
- 处理了 selector 为 HTML 字符串的情况
- 处理了 selector 为 DOM 元素的情况
- 处理了 selector 为函数的情况
各种参数格式的处理
根据 init() 方法的逻辑判断的结构,我将根据传入的参数分为五种情况进行讨论:
- ‘’、null、undefined、false 等其值为“假”的变量
- 字符串,包括:
- html:HTML 代码串
- #id: 元素 id
- expr:选择器
- expr, context:选择器和上下文元素
- expr, $(…):选择器和 jQuery 对象
- singleHTML, propertyObj:单个 HTML 标记和待添加属性构成的对象
- DOM 元素对象
- 函数
- jQuery 对象
1. “假” 变量
|
直接返回一个 jQuery 实例对象。
2. 字符串
字符串的情况比较多,而且复杂。
2.1. 入口
进入字符串处理的分支:
2.2. 匹配字符串
如果当前 selector 是以 “<” 开头,以 “>” 结尾的话,也就是说此时是 HTML 标记的字符串时,跳过正则式的检查,手动把 match 设置为 [ null, selector, null ]:
否则就进行正则式的匹配:
2.3. 检查是否 HTML 串或 #id
当:匹配的是 HTML 串;或是 #id 情况且没有设定 context 上下文的情况
(如果不符合条件,跳至第7步 )
2.4. 一般 HTML 串
如果 match[1] 存在,也就是说 selector 为 HTML 标记的字符串,处理方式是将 HTML 串解析生成对应的 DOM 元素,并存放成数组,与 this 合并,存放在 this 中 ( $(html) -> $(array) )
通过 jQuery.merge() 方法,将得到的 DOM 对象和当前实例 this 合并,并保存在 this 里
( merge() 可以合并两个数组内容到第一个数组 )
因为 selector 是 HTML 字符串,所以就要提取里面的标签,并转化为 DOM 对象。
而上面的jQuery.parseHTML() 就能起到这个作用(@:具体可见附录Attachment了解)。这个方法最后返回一个 DOM 对象,并且已经有了父子节点的层次关系。
另外,在当前使用这个方法中时,还传入了 context 上下文。有这么一句:
context && context.nodeType ? context.ownerDocument || context : document
拓展
- ownerDocument 是 Node 对象的一个属性,返回的是某个元素的根节点文档对象,即 document 对象
- documentElement 是 Document 对象的属性,返回的是文档根节点
- 对于 HTML 文档来说,documentElement 是 标签对应的 Element 对象,ownerDocument 是 document 对象
2.5. 单个 HTML 标签
如果传入的 selector 字符串是单个的 HTML 标记,并且 context 是一个存放有待添加的属性及其值的对象,那么在这里就会遍历所有属性,将其添加到 this 里的 DOM 元素。
2.6. 元素 id
如果 selector 是 #id 的话,就直接在 document 中查找 id 为 selector 的元素,如果找到则保存到 this 中。
并且,会增加一个属性值为 参数字符串、document 的 selector、context 属性
2.7. CSS 选择器 + jQuery 对象
如果是这种情况,就在给定的 context (没给定的话就是在 rootjQuery 中) 中查找匹配该选择器的元素集合并返回。
2.8. CSS 选择器 + DOM 元素对象
如果给定的不是 jQuery 对象而是 DOM 对象,就用它来构造一个相应的 jQuery 对象,然后再以该 jQuery 对象为上下文来查找。
3. DOM 元素
直接将该 DOM 对象存放在 this 中
4. 函数
如果是函数,则当 rootjQuery 加载完成后执行该函数。
等价于 jQuery(document).ready(function(){});
5. jQuery 对象
当传入的 selector 是一个 jQuery 对象时,其实类似于 #id 的情况,保存 selector 和 context 属性
Attachment
$.parseHTML()
|
结果: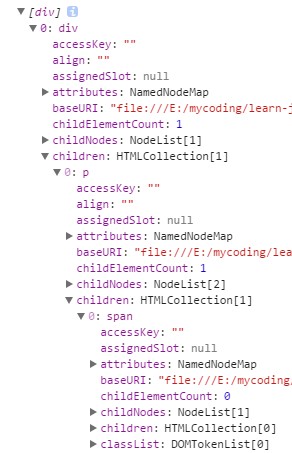
parseHTML() 的源码如下:
$.buildFragment()
挖坑待填。。。