缓存,就是复用一些更新不是很频繁的网络资源,以此来减少请求数量,或者是减少带宽占用,提升服务器响应时间。
分类
- 私有缓存
(浏览器缓存) - 公有缓存
(缓存代理服务器(cdn)或代理缓存)
优点
- 减少冗余的数据传输,节省流量
- 缓解带宽瓶颈问题
- 缓解瞬间拥塞,降低对原始 server 的要求
- 降低了距离延时(因为离服务器较远地方的客户端加载页面较慢)
处理流程
下面是一个简化版的 web 缓存处理流程。
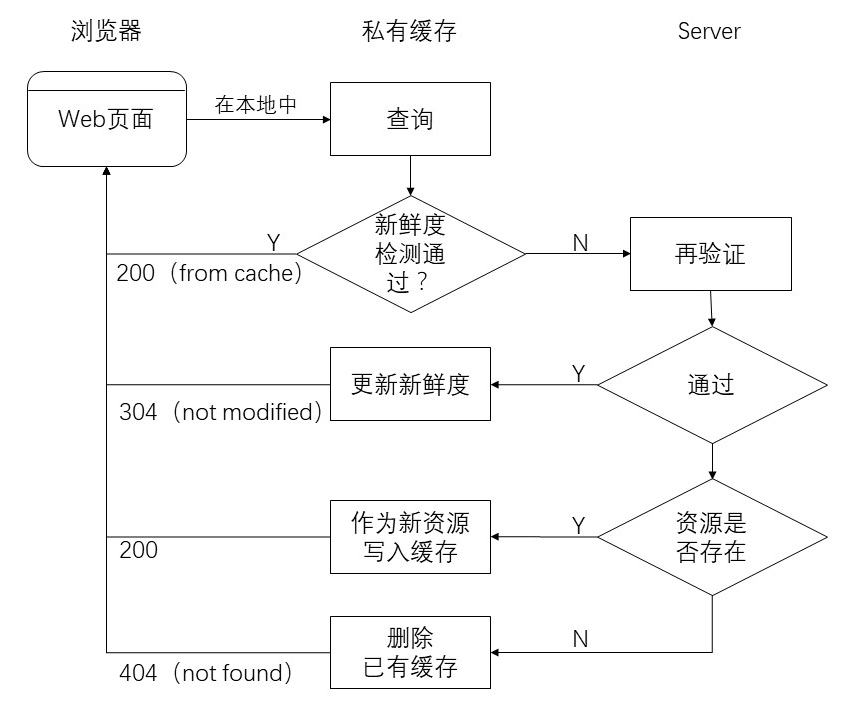
下面将对处理流程的细节进行讲解。
新鲜度检测
新鲜度检测,就是根据一个“保质期”来判断一个缓存是否在有效期中。
那么这个“保质期”是什么?怎么来的?
简单来讲,其实它就是 HTTP 通过缓存机制,将服务器资源的副本在客户端保留的时间。在这个有效期内,浏览器可以重复使用这个缓存资源;反之,就将它视为过期资源,并清理掉。
下面讲讲检测相关的请求头字段:
Cache-Control
这是 HTTP 1.1 新增的字段,表示资源缓存的过期时间,其值是一个时间值(以秒为单位),是一个相对时间。
当然,CC 这个字段不只是设置一个时间而已,它还有一些属性值
| 属性值 | 解释 | 备注 |
|---|---|---|
| max-age | 指定缓存最大的存放时间。在这段时间内不会再向服务器请求 | 参数是单位为秒的正整数 |
| public | 指定响应的资源可以在公有缓存中被缓存,从而被多用户共享 | 默认值 |
| private | 指定响应资源只能在私有缓存中缓存 | (与 public 相对) |
| no-cache | 表示必须先与服务器确认该资源是否被更改过,再决定是否使用私有缓存 | 依靠 Etag & If-None-Match 来判断 |
| no-store | 表示禁止缓存,每次都会下载一个新的资源 | 用于机密性资源 |
p.s.
- Cache-Control 也可以在请求头中设置。在这里设置的好处是,通过设置 max-age=0 可以直接向 server 确认是否有修改。
- no-cache 会强制每次请求直接发送到源 server,而不经过缓存版本的验证。
Expires
HTTP 1.0 规范中的字段,同样也是表示资源缓存的过期时间。和 Cache-Control 的区别在于后者是使用相对时间,而它是使用绝对时间。
但由于可能会存在一种情况,客户端和服务端的时间可能不一致,所以缓存版本会有偏差。
服务器再验证
缓存的资源过期了,这时客户端会发送请求获取新的资源,服务器会核对对应资源是否有更改。
验证方式
HTTP 1.1: If-None-Match + ETag
第一次获取资源的请求中,响应头会返回 ETag 字段,ETag 的值是一个由服务端生成的有唯一性的 hash 值。
浏览器会把 ETag 保存下来。
在以后的请求中,会在请求头中添加 If-None-Match,值为 ETag 的值,发到服务端。服务端根据传的这个值验证资源是否过期,再根据验证结果来进行相应操作。
HTTP 1.0: If-Modified-Since + Last-Modified
这两个字段的值都是具体日期,具体的验证方式,和上面的相似。
但值得注意的是,由于比对的是资源文件的最近修改时间,有些时候,可能会对文档进行周期性的重写,或者是其他的操作(去掉注释或者测试代码等不改变功能的代码块),这会更新了最近修改时间,就会产生了不必要的响应。